CodeFusion Paper Removed After Leaking ChatGPT Parameters
Published on November 1, 2023.
Update: The authors added a withdrawal comment, citing a Forbes article that mentioned 20B parameters.
On October 26, researchers working for Microsoft published a paper relating their groundbreaking innovation which they dubbed CodeFusion. They claimed that a 75 million parameter CodeFusion model could generate higher quality code than ChatGPT (with billions of parameters) and StarCoder (with over 15 billion parameters) using autoregressive methods. This means that, if true, the model could generate code and correct previously generated tokens.
They published their paper to arXiv and it quickly became very popular in the AI community, however they did not release the inference code or pre-trained models.
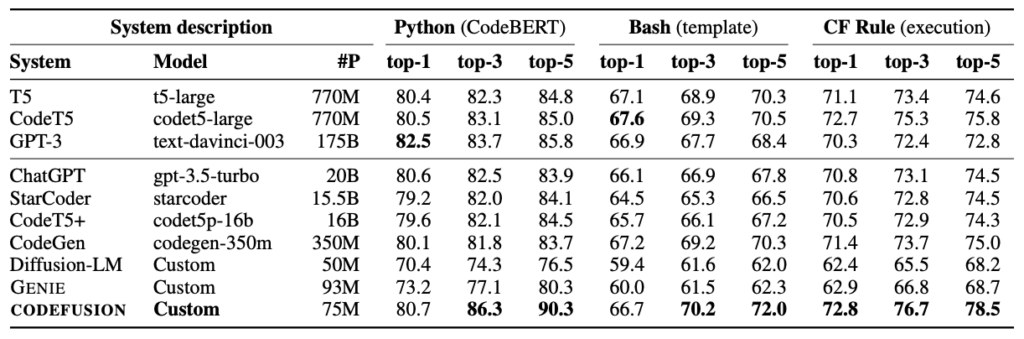
The part of the paper that most shocked the AI community wasn’t the implementation itself, but a figure in the paper. The figure, Table 1, compared the quality of CodeFusion generations to LLMs. The table included the system, model, parameter count, and evaluations.
It listed ChatGPT (gpt-3.5-turbo) as having only 20 billion parameters.
The parameter count of ChatGPT was never released and many have surmised that it contained 175 billion parameters. This table, however, claimed it only had 20B. This would be an incredible innovation, as models with over 3 times as many parameters do not come close to the accuracy of ChatGPT. The only explanation would be that OpenAI trained ChatGPT on truly massive amounts of data. This is truly shocking.
Although some might discredit this information as simply a random paper, many have found reason to believe it because it comes from Microsoft. Microsoft has proved itself to be a close partner with OpenAI, forming partnerships with it to create Bing chat and hosting it on Azure.
But then, Microsoft took the paper down. As @felix_red_panda noticed, the authors of the paper withdrew it from online sources. Soon, the PDF was removed from arXiv and all versions seemed to disappear. Thankfully, due to the Internet Archive, the paper can still be obtained today.
One can only surmise why Microsoft retracted the paper, however the evidence seems to strongly suggest that ChatGPT may in fact only contain 20 billion parameters. If this is true, open source models may soon reach ChatGPT-level capabilities. The software engineer @anton asked on X:
So what do we think, mistral 20B > gpt-3.5 capabilities?
(Mistral is a 7B open-source model that exceeds many 13B models)
In their comment when removing the paper from arXiv, the authors stated:
Contains inappropriately sourced conjecture of OpenAI’s ChatGPT parameter count from this http URL, a citation which was omitted. The authors do not have direct knowledge or verification of this information, and relied solely on this article, which may lead to public confusion
So what do you think? Does ChatGPT contain only 20 billion parameters? Or is it just a mistake? Post what you think in the comments!
Also, if you want to read the paper, here’s an archive. It’s licensed under CC-BY on arXiv.